Better bandit building: Advanced personalization the easy way with AutoML Tables
Zi Yang
Cloud Technical Resident; Google Cloud Bandits Solutions team
As demand grows for features like personalization systems, efficient information retrieval, and anomaly detection, the need for a solution to optimize these features has grown as well. Contextual bandit is a machine learning framework designed to tackle these—and other—complex situations.
With contextual bandit, a learning algorithm can test out different actions and automatically learn which one has the most rewarding outcome for a given situation. It’s a powerful, generalizable approach for solving key business needs in industries from healthcare to finance, and almost everything in between.
While many businesses may want to use bandits, applying it to your data can be challenging, especially without a dedicated ML team. It requires model building, feature engineering, and creating a pipeline to conduct this approach.
Using Google Cloud AutoML Tables, however, we were able to create a contextual bandit model pipeline that performs as good or better than other models, without needing a specialist for tuning or feature engineering.
A better bandit building solution: AutoML Tables
Before we get too deep into what contextual bandits are and how they work, let’s briefly look at why AutoML Tables is such a powerful tool for training them. Our contextual bandits model pipeline takes in structured data in the form of a simple database table, uses the contextual bandit and meta-learning theories to perform automated machine learning, and creates a model that can be used to suggest optimal future actions related to the problem.
In our research paper, “AutoML for Contextual Bandits”—which we presented at the ACM RecSys Conference REVEAL workshop—we illustrated how to set this up using the standard, commercially available Google Cloud product.
As we describe in the paper, AutoML Tables enables users with little machine learning expertise to easily train a model using a contextual bandit approach. It does this with:
Automated Feature Engineering, which is applied to the raw input data
Architecture Search to compute the best architecture(s) for our bandits formulation task—e.g. to find the best predictor model for the expected reward of each episode
Hyper-parameter Tuning through search
Model Selection where models that have achieved promising results are passed onto the next stage
Model Tuning and Ensembling
This solution could be a game-changer for businesses that want to perform bandit machine learning but don’t have the resources to implement it from scratch.
Bandits, explained
Now that we’ve seen how AutoML Tables handles bandits, we can learn more about what, exactly, they are. As with many topics, bandits are best illustrated with the help of an example. Let’s say you are an online retailer that wants to show personalized product suggestions on your homepage.
You can only show a limited number of products to a specific customer, and you don’t know which ones will have the best reward. In this case, let’s make the reward $0 if the customer doesn’t buy the product, and the item price if they do.
To try to maximize your reward, you could utilize a multi-armed bandit (MAB) algorithm, where each product is a bandit—a choice available for the algorithm to try. As we can see below, the multi-armed bandit agent must choose to show the user item 1 or item 2 during each play. Each play is independent of the other—sometimes the user will buy item 2 for $22, sometimes the user will buy item 2 twice earning a reward of $44.
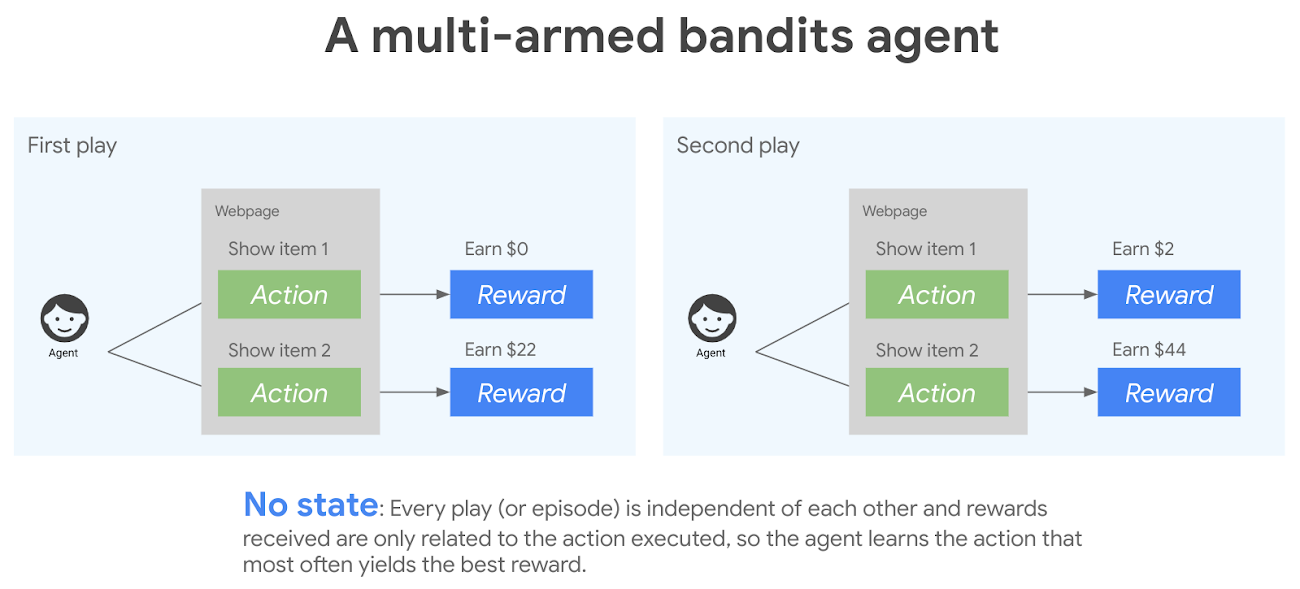
The multi-armed bandit approach balances exploration and exploitation of bandits.
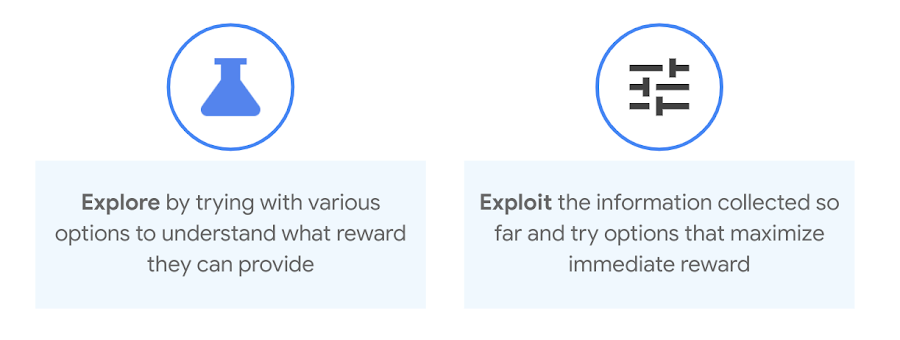
To continue our example, you probably want to show a camera enthusiast products related to cameras (exploitation), but you also want to see what other products they may be interested in, like gaming gadgets or wearables (exploration). A good practice is to exploit more at the beginning, when the agent’s information about the environment is less accurate, and gradually adapt this policy as more knowledge is gained.
Now let’s say we have a customer that’s a professional interior designer and an avid knitting hobbyist. They may be ordering wallpaper and mirrors during working hours and browsing different yarns when they’re home. Depending on what time of day they access our website, we may want to show them different products.
The contextual bandit algorithm is an extension of the multi-armed bandit approach where we factor in the customer’s environment, or context, when choosing a bandit. The context affects how a reward is associated with each bandit, so as contexts change, the model should learn to adapt its bandit choice, as shown below.
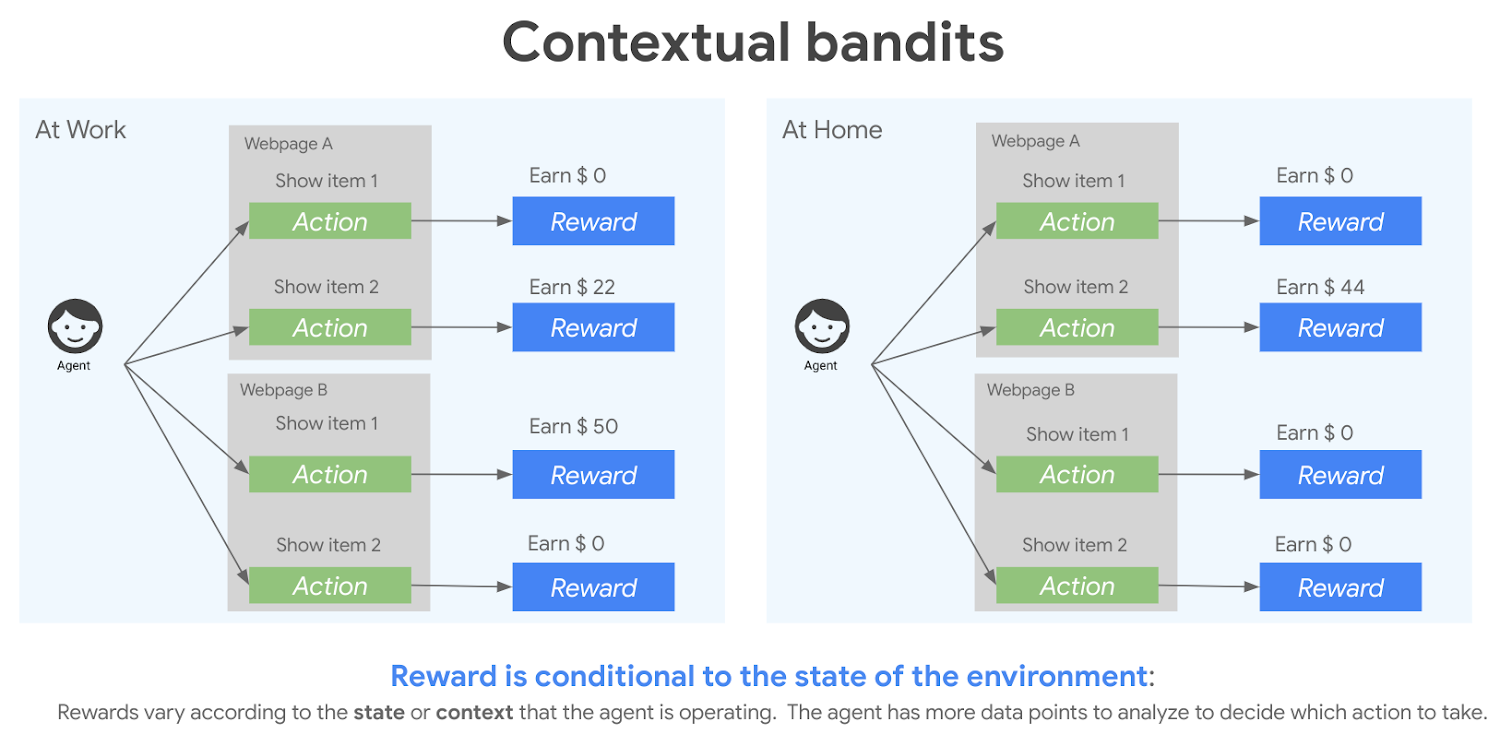
Not only do you want your contextual bandit approach to find the maximum reward, you also want to reduce the reward loss when you’re exploring different bandits. When judging the performance of a model, the metric that measures reward loss is regret—the difference between the cumulative reward from the optimal policy and the model’s cumulative sum of rewards over time. The lower the regret, the better the model.
How contextual bandits on AutoML Tables measures up
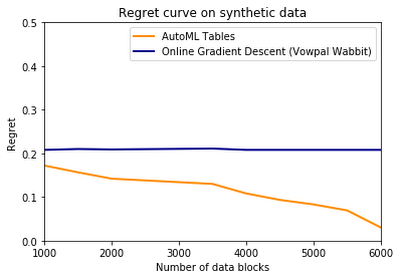
In “AutoML for Contextual Bandits” we used different data sets to compare our bandit model powered by AutoML Tables to previous work. Namely, we compared our model to the online cover algorithm implementation for Contextual Bandit in the Vowpal Wabbit library, which is considered one of the most sophisticated options available for contextual bandit learning.
Using synthetic data we generated, we found that our AutoML Tables model reduced the regret metric as the number of data blocks increased, and outperformed the Vowpal Wabbit offering.
We also compared our model’s performance with other models on some other well-known datasets that the contextual bandit approach has been tried on. These datasets have been used in other popular work in the field, and aim to test contextual bandit models on applications as diverse as chess and telescope data.
We consistently found that our AutoML model performed well against other approaches, and was exceptionally better than the Vowpal Wabbit solution on some datasets.

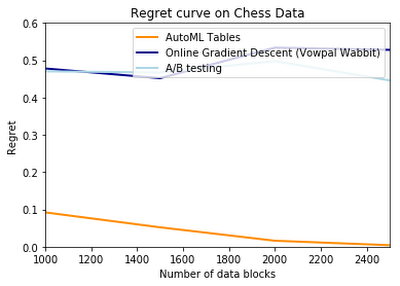
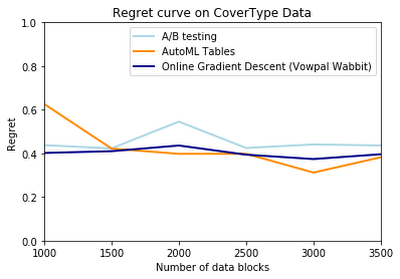
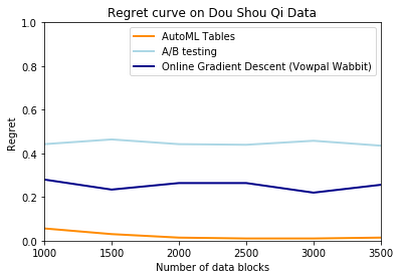
Contextual bandits is an exciting method for solving the complex problems businesses face today, and AutoML Tables makes it accessible for a wide range of organizations—and performs extremely well, to boot. To learn more about our solution, check out “AutoML for Contextual Bandits.” Then, if you have more direct questions or just want more information, reach out to us at google-cloud-bandits@google.com.
The Google Cloud Bandits Solutions Team contributed to this report: Joe Cheuk, Cloud Application Engineer; Praneet Dutta, Cloud Machine Learning Engineer; Jonathan S Kim, Customer Engineer; Massimo Mascaro, Technical Director, Office of the CTO, Applied AI



