Vertex Matching Engine: Blazing fast and massively scalable nearest neighbor search

Anand Iyer
Group Product Manager, Vertex Generative AI
Some of the handiest tools in an ML engineer’s toolbelt are vector embeddings, a way of representing data in a dense vector space.
An early example of the usage of embeddings is that of word embeddings. Word embeddings became popular because position (distance and direction) in the vector space can encode meaningful semantics of each word. For example, the following visualizations of real embeddings show geometrical relationships that capture semantic relations like the relation between a country and its capital:
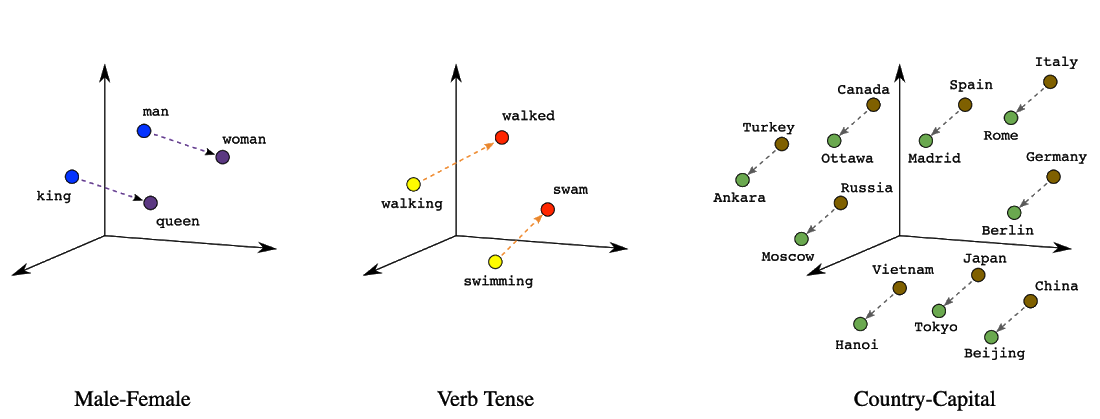
Figure 1. Embeddings can capture meaningful semantic information
Today, word or text embeddings are commonly used to power semantic search systems. Embedding-based search is a technique that is effective at answering queries that rely on semantic understanding rather than simple indexable properties. In this technique, machine learning models are trained to map the queries and database items to a common vector embedding space, such that semantically similar items are closer together. To answer a query with this approach, the system must first map the query to the embedding space. It must then find, among all database embeddings, the ones closest to the query; this is the nearest neighbor search problem (which is sometimes also referred to as ‘vector similarity search’).
Figure 2: The two-tower neural network model, illustrated above, is a specific type of embedding-based search where queries and database items are mapped to the embedding space by two respective neural networks. In this example the model responds to natural-language queries for a hypothetical literary database.
The use of embeddings is not limited to words or text. With the use of machine learning models (often deep learning models) one can generate semantic embeddings for multiple types of data – photos, audio, movies, user preferences, etc. These embeddings can be used to power all sorts of machine learning tasks.
One example is image similarity search: using image embeddings, you can use one image to search for other similar images (like Google Image Search). Or, by generating embeddings for customers, using their purchase histories, one can find other similar customers or products, to provide better recommendations.
The applications of embeddings are truly vast, and power everything from:
Recommendation engines
Search engines
Ad targeting systems
Image classification or image search
Text classification
Question answering
Chat bots
and much more...
What’s more, even though some applications might require you to build your own models to generate embeddings (like modeling your own unique customers), many models to generate embeddings are free to use and open-source, like the Universal Sentence Encoder for text or ResNet for images. This makes vector embeddings an especially useful ML technique when you haven’t got a lot of your own training data.
However, despite the fact that vector embeddings are an extraordinarily useful way of representing data, today’s databases aren’t designed to work with them effectively. In particular, they are not designed to find a vector’s nearest neighbors (e.g. what ten images in my database are most similar to my query image?). It’s a computationally challenging problem for large datasets, and requires sophisticated approximation algorithms to do quickly and at scale.
That’s why we’re thrilled to introduce Vertex Matching Engine, a blazingly fast, massively scalable and fully managed solution for vector similarity search.
Vertex Matching engine is based on cutting edge technology developed by Google research, described in this blog post. This technology is used at scale across a wide range of Google applications, such as search, youtube recommendations, play store, etc.
Let's look at some notable capabilities of Vertex Matching Engine:
Scale: It enables searching over billions of embedding vectors, at high queries per second, with low latency. With a typical nearest neighbor service that enables searches over millions of vectors, you can build cool AI applications. However, with a service that enables searching over billions of vectors, one can build truly transformative applications.
Lower TCO: To design a service that works at the scale of billions of vectors, one has to make it resource efficient. After all, just throwing more hardware at the problem will not scale. Due to the resource efficiency of Google’s technology, in real world settings, Vertex Matching Engine can be ~40% cheaper than leading alternatives (Google Cloud internal research, May 2021).
Low latency with high recall: Searching over a really large collection of embedding vectors, at high queries per second while serving results with low latency, will not be possible if the system performed a brute force search. It necessitates the use of sophisticated approximation algorithms that exchange some accuracy for massive speed and scale. This paper describes the underlying techniques in more detail. Fundamentally, the system tries to find most of the nearest neighbors, at very low latency. Recall is a metric used to measure the percentage of true nearest neighbors returned by the system. Based on empirical statistics from teams within Google, we know that for many real world applications, Vertex Matching Engine can achieve recall of 95-98%, while serving results with 90th percentile latency less than 10 ms (Google Cloud internal research, May 2021).
Fully managed: The Matching Engine is an autoscaling fully managed solution, so that you don't have to worry about managing infrastructure, and can focus on building cool applications.
Built-in filtering: For real world applications, semantic similarity via vector matching often goes hand in hand with other constraints or criterion used to filter results. For example, while making recommendations an e-commerce website may perform filtering based on product category or region of the user. Vertex Matching Engine enables users to perform simple or complex filtering using boolean logic.
How to use Vertex Matching Engine
Users provide pre-computed embeddings via files on GCS. Each embedding has an associated unique ID, and optional tags (a.k.a tokens or labels) that can be used for filtering. Matching Engine ingests the embeddings and creates an index. The index is then deployed on a cluster, at which point it is ready to receive online queries for vector similarity matching. Clients can call the index with a query vector, and specify the number of nearest neighbors to return. The IDs of the matched vectors are then returned to the client, along with their corresponding similarity scores.
In real world applications it is common to update embeddings or generate new embeddings at a periodic interval. Hence, users can provide an updated batch of embeddings to perform an index update. An updated index will be created from the new embeddings, which will replace the existing index with zero downtime or zero impact on latency.
While creating an index, it is important to tune the index to adjust the balance between latency and recall. The key tuning parameters are described here. Matching Engine also provides the ability to create brute-force indices, to help with tuning. A brute-force index is a convenient utility to find the “ground truth” nearest neighbors for a given query vector. It performs a naive brute force search. Hence it is slow and should not be used in production. It is only meant to be used to get the “ground truth” nearest neighbors, so that one can compute recall, during index tuning.
Preferred cloud for sophisticated ML/AI applications
Customers often pick Google Cloud to get access to the amazing infrastructure Google has developed for its own AI/ML applications. With the Matching Engine, we are excited to make one more industry leading Google service available to our customers. We can’t wait to see all the amazing applications our customers build with this service.
To get started, please take a look at the documentation here, and this sample notebook.