Demystifying Cloud Spanner multi-region configurations
Neha Deodhar
Software Engineering Manager, Cloud Spanner
Cloud Spanner is a strongly consistent, highly scalable, relational database. It powers billion-user products every month. In order to provide high availability and geographic locality, Cloud Spanner creates multiple copies (aka replicas) of your data and then stores these replicas across different geographical locations. This blog post discusses what this entails.
To create a database in Cloud Spanner, you first need to create an instance. An instance specifies the replication topology and resources that will be used by all the databases within that instance. There are two types of instances:
Regional (or Single region) - In regional instances, all the database replicas are in a single geographical region. This is a good option if your application resides in a single geographical region and you need to be resilient to zone failures or other hardware failures, but don’t need to survive region failure.
Multi-region - In multi-region instances, the database is replicated across multiple regions. This is a good option if your application needs to survive region failure, or you want to scale your application to new geographies, or your users are globally distributed and you want to reduce read latency by having a copy of your database close to them.
While creating an instance, you can choose the number of nodes for that instance. Note that a “node” in Cloud Spanner is different from a “replica”. A node denotes the amount of serving and storage resources that will be available to an instance. For example, a 1-node regional instance and a 2-node regional instance will both have 3 replicas of the data. The difference is that the 2-node instance will have twice the serving and storage resources compared to the 1-node instance.
Once an instance and its nodes are created, you can create databases within that instance. Each instance can have a maximum of 100 databases. The databases will share the serving and storage resources of that instance. In order to scale your database, you simply need to add more nodes to the instance. Note that adding a new node won’t change the number of replicas but will add more serving (CPU and RAM) and storage resources, increasing your application’s throughput.
Let us now understand how regional and multi-region instances differ and how to choose the configuration that works best for you.
Single region instances
In single-region instances, Cloud Spanner will create 3 replicas of your data and distribute those across 3 failure domains, called zones, within a single geographical region. For example, the diagram below shows a regional us-east1 configuration. Any instance created using this configuration will have 3 database replicas distributed across 3 zones in us-east1.
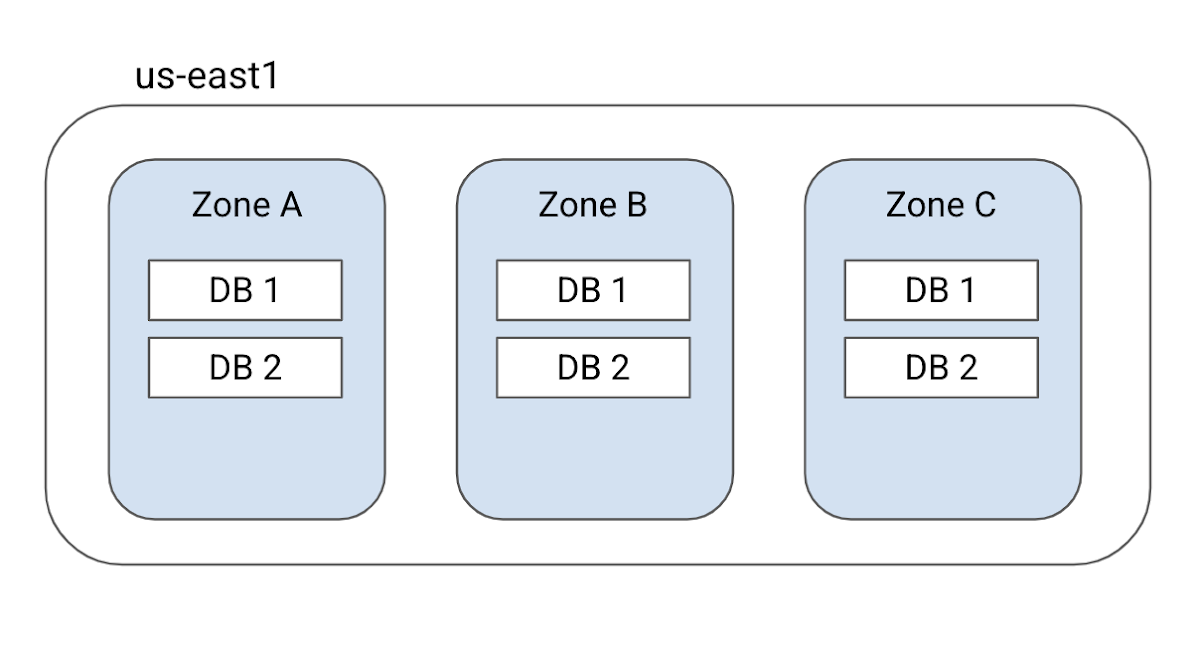
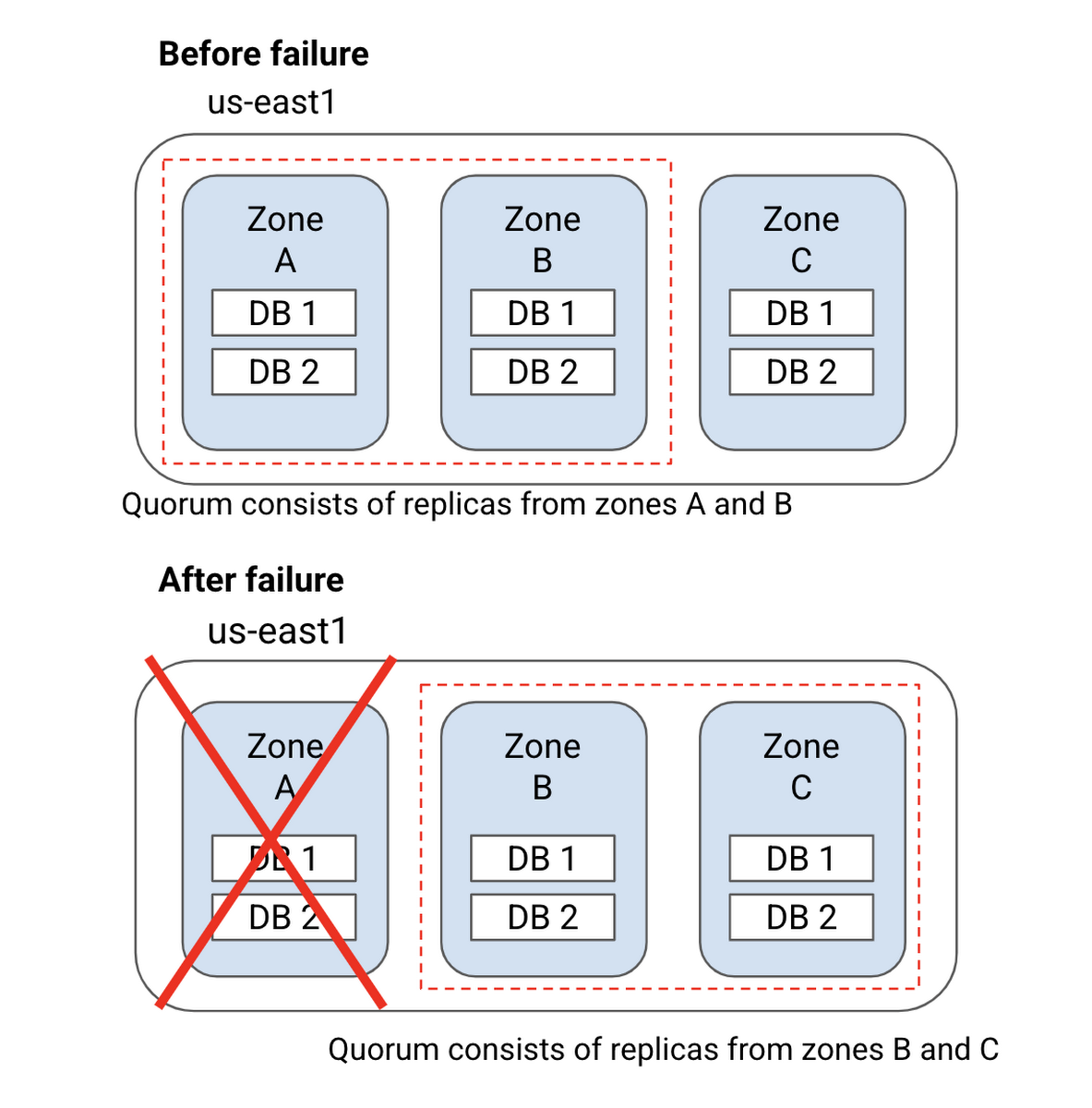
Each replica contains a full copy of your database and can serve read-write as well as read-only requests. To provide strong data consistency, Cloud Spanner uses a synchronous, Paxos-based replication scheme, in which replicas take a vote on (or acknowledge) every write request. A write is committed when a majority of the replicas, called a quorum, agree to commit the write.
For single-region instances, this means that 2 out of the 3 replicas have to agree to commit the write and such instances can thus survive a zone failure.
Multi-region instances
For multi-region configurations, Cloud Spanner will create at least 5 replicas of your data and distribute them across 3 or more regions. Two of the regions will each have two read-write replicas of the data distributed across two zones while a third region will have a single, special type of replica called a “witness” replica. Below is an example nam3 multi-region configuration. It has 2 replicas each in us-east4 and us-east1 regions and a witness replica in us-central1 region.
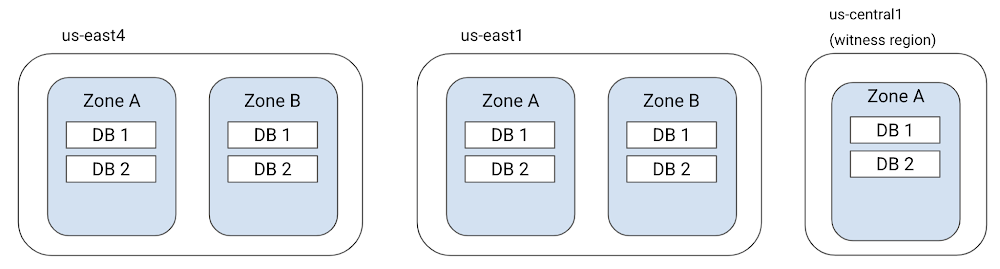
Witness replicas don’t store a full copy of your database. However, they participate in voting to commit a write. Adding witness replicas makes it easier to achieve quorums for writes without requiring a full replica. To understand why witness replicas are useful, consider that you have a database that needs to survive region failure and has application traffic from two regions. If you only have replicas in the two regions and no third region, then you cannot construct a majority quorum that could survive the loss of either region. To mitigate this, we use a witness replica in a third region.
Typically, the witness replica region will be close to one of the two read-write regions, such that a majority quorum of the witness and the closeby region can be used to quickly commit the writes. Note, however, that this is not always the case and some Cloud Spanner configurations have the two read-write regions close to each other (forming a quorum) and a witness region that is slightly further away. Since witness replicas don’t store a full copy of the data, they cannot serve read requests.
As with any decision, there are tradeoffs involved in choosing between single and multi-region instances. Multi-region instances give you higher availability guarantees (99.999% availability) and global scale. However, it comes at the cost of higher write latencies. Since every write needs quorum across replicas from two regions, the writes will have higher latencies compared to those in single region instances.
Below is a table summarizing the differences between regional and multi-regional configurations.
Regional | Multi-region |
Data is stored in a single geographical region | Data is replicated across multiple geographical regions |
Useful for applications that reside in a single region or have regional data governance requirements | Useful for applications that want to scale reads across multiple geographies |
Can survive zone failure | Can survive region failure |
Low latency reads and writes within region | Higher write latency, low latency reads from multiple geographies |
99.99% availability | 99.999% availability |
Let’s now look at some interesting options for multi-region configurations. To do that, let's first understand how Spanner replication works.
Replication and Leader replicas
Cloud Spanner divides your data into chunks called “splits”. Each split has multiple copies, or replicas. In order to ensure strong consistency, one of those replicas is elected (using Paxos) to act as a leader for the split.
The leader replica for a split is responsible for handling writes. All client write requests will first go to the leader, which logs the write and then sends it to the other voting replicas. After each replica completes the write, it responds back to the leader and votes whether the leader should commit the write. When a majority of the voting replicas vote to commit the write, the leader considers the write as committed.
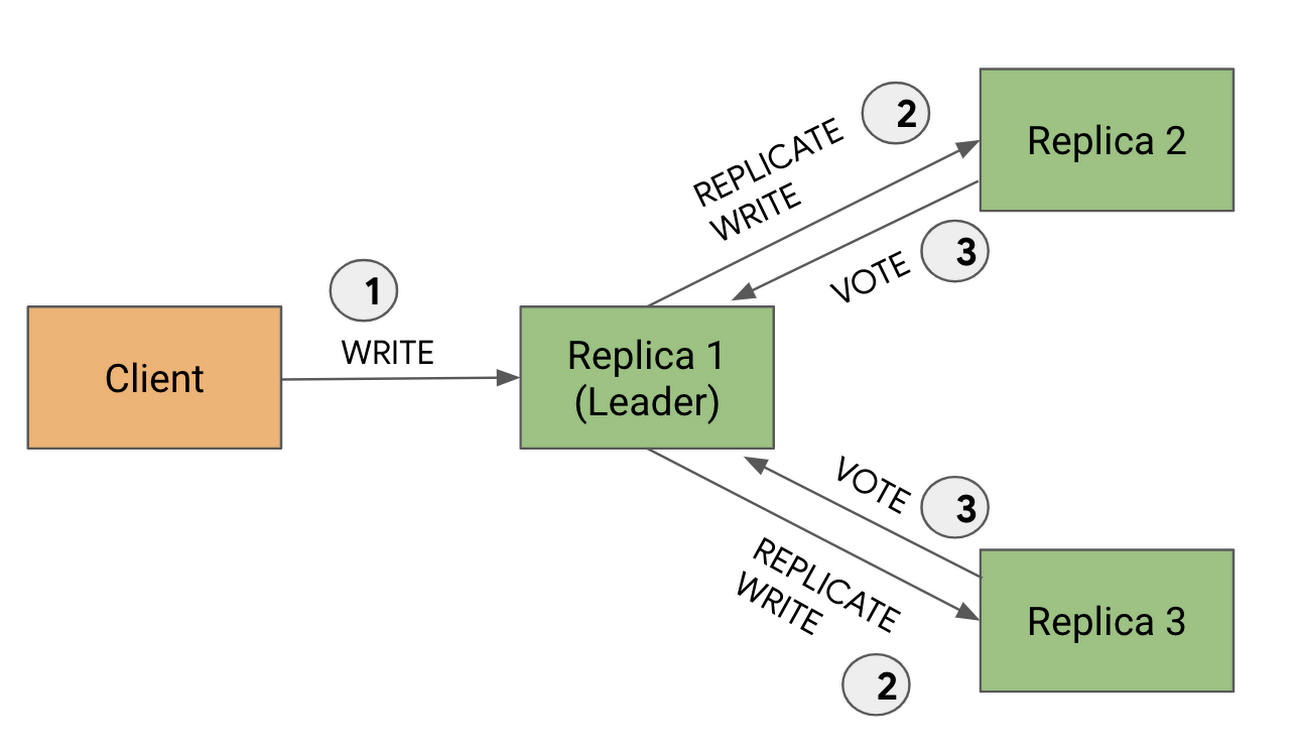
Preferred leader region
In multi-region instances, the splits are replicated across multiple regions. If the leaders for splits were randomly assigned across regions, it could have an impact on your application performance, especially write traffic and to some extent, strong read traffic. For example, consider that your application is in us-east4. For splits that have leaders in the same region (us-east4), your application will have good latency but for splits that have leaders in a different region (say us-east1), your application will see higher latency.
To have better latency predictability and control over performance, Cloud Spanner multi-region instances have a default (preferred) leader region. Cloud Spanner will place the database’s leader replicas in the default leader region whenever possible. In order to get the best latency, we recommend applications do writes in the same region as or in a region that is close to the default leader region.
Handling region failure
If the preferred leader region fails or becomes unavailable, Cloud Spanner moves the leaders to another region. There could be a delay of a few seconds (less than 10 seconds) for Cloud Spanner to detect that the leader is no longer available and elect a new leader. During this time, applications could see higher read and write latencies. Cloud Spanner is robust to intermittent errors and will transparently retry client requests. This ensures that applications don’t see any downtime but only see a brief increase in latencies. Note that when the preferred leader region comes back up, the leaders will automatically move back to the preferred region, without downtime or latency impact on applications.
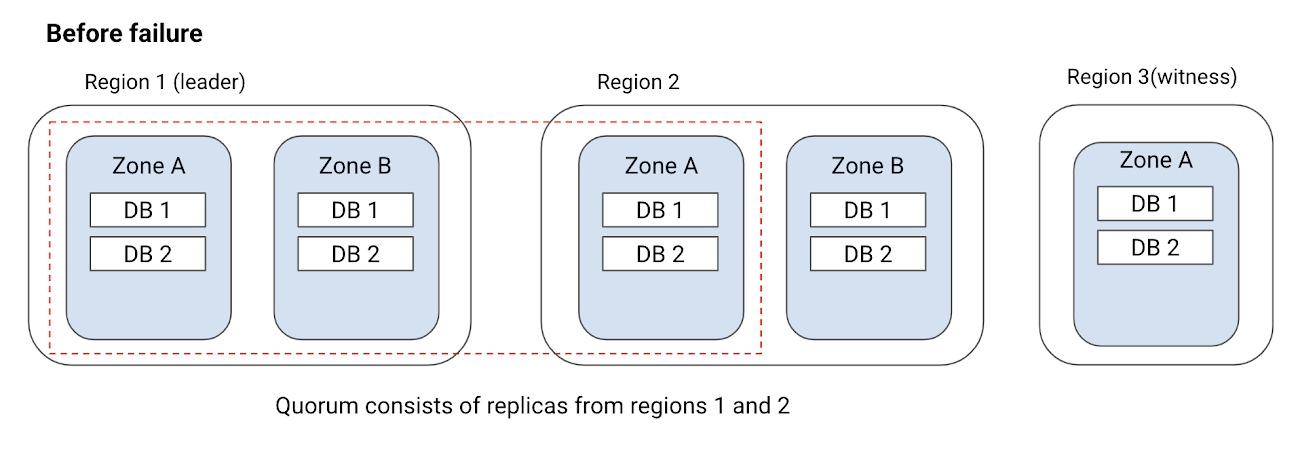
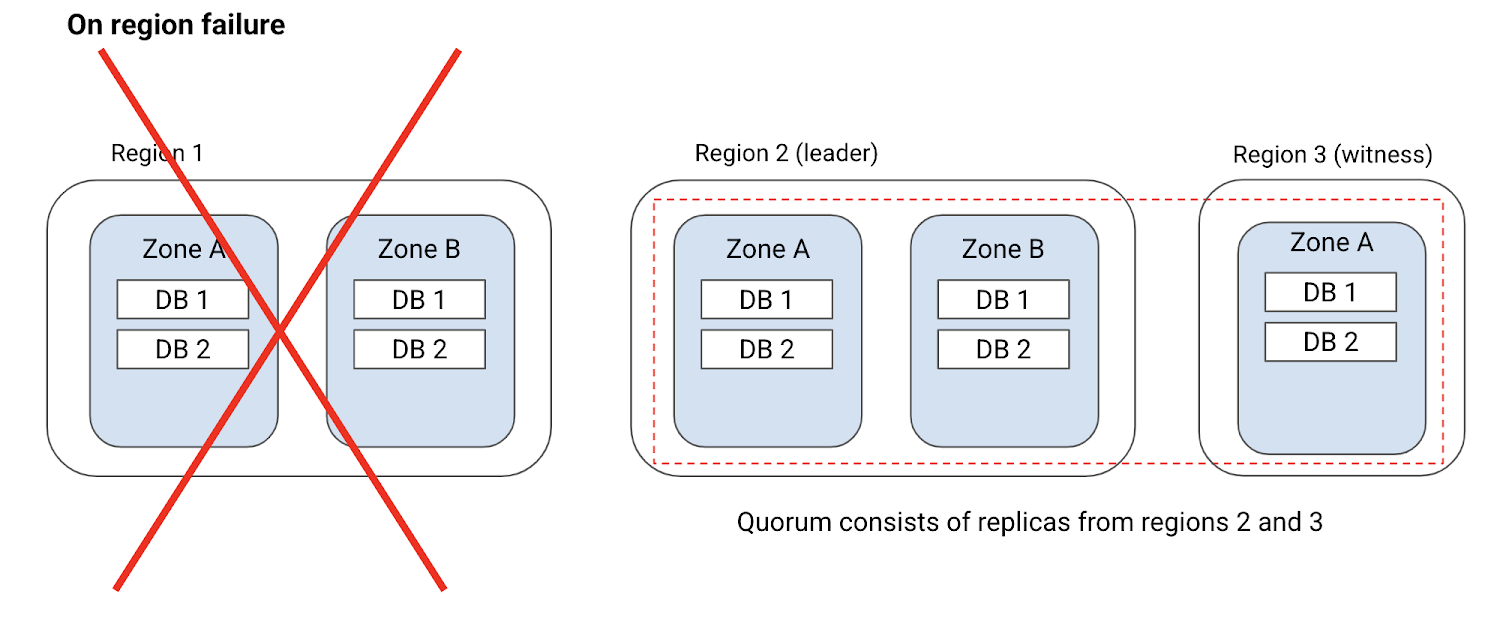
Handling zone failure
If a zone within the preferred leader region becomes unavailable, then Cloud Spanner will move all the leaders to the other zone within the preferred leader region and continue to maintain the preferred leader setting.
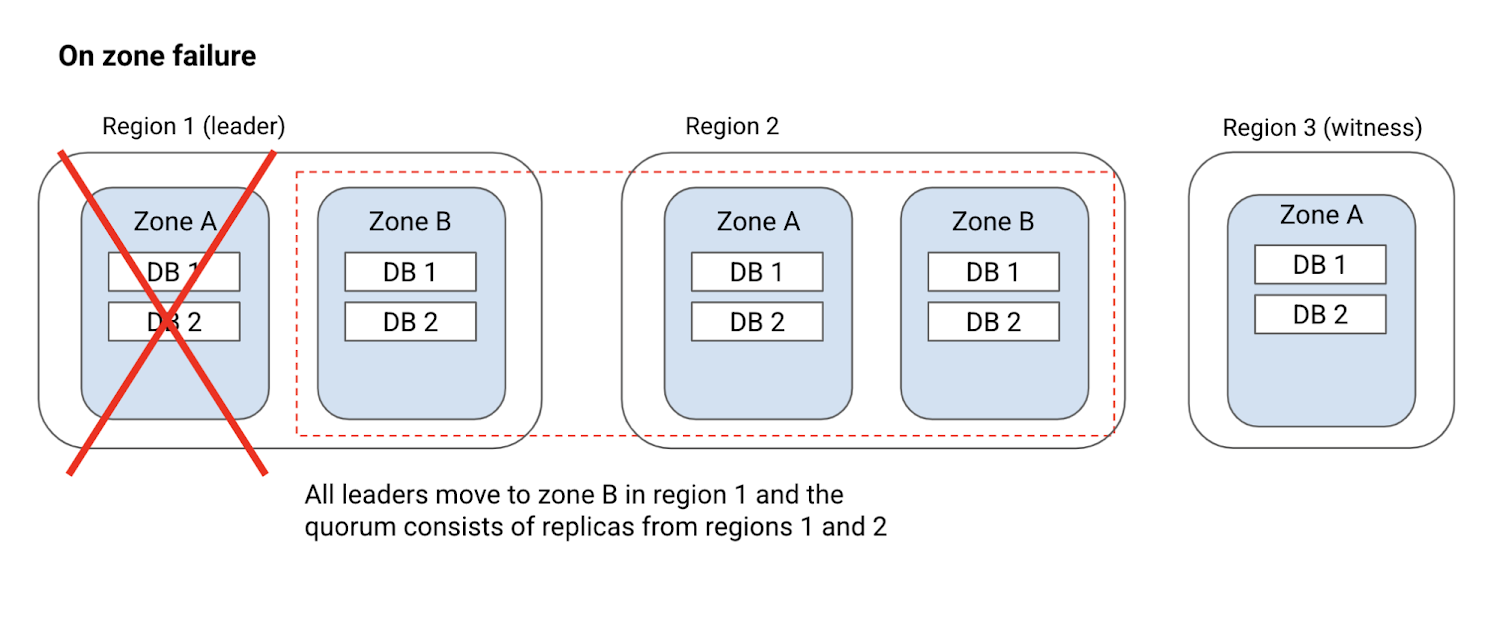
As seen in the above diagram, even when zone A fails, region 1 continues to be the leader region and all the leaders move to zone B of region 1.
Read-only replicas
One interesting type of replica supported in Cloud Spanner multi-region configurations is a read-only replica. This is useful for serving low latency reads in remote regions. As an example, consider that you have a globally distributed e-commerce application. If you use read-write replicas across regions in North America, Asia and Europe, then your writes will see very high latencies due to cross-continent replication. To mitigate that, you can limit the read-write replicas to regions within a single continent, say North America, and add read-only replicas in regions in Europe and Asia. Since read-only replicas don’t participate in voting for a write, your writes will see low latencies. At the same time, the read-only replicas will let you serve low latency reads in Europe and Asia.
Strong and stale reads
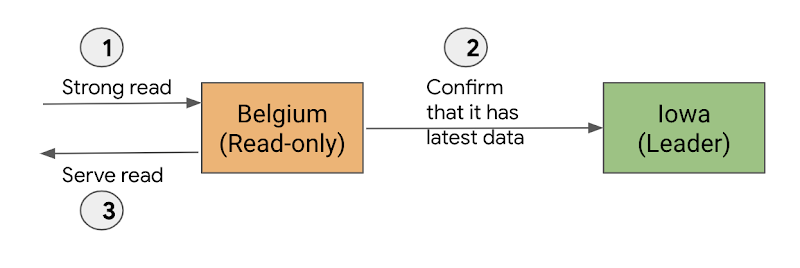
Reads in Cloud Spanner will, by default, always read the latest data. Such reads are called strong reads and Cloud Spanner will guarantee that you will see all data that has been committed up until the start of the read. Strong reads can be served by any replica. However, the replica may need to communicate with the leader to confirm that it has the latest data to serve the read. As a result, such reads may see higher latency when the read is served by a replica that is in a different region than the leader. Note that in many cases, the replica knows from its internal state if it has caught up enough and can serve the reads. However, if it is not sure, it communicates with the leader and then waits to catch up before serving the read.
If your application is latency sensitive but can tolerate stale data, then stale reads are a good option. These reads are done at a timestamp in the past and can be served by the closest replica that is caught up until that timestamp. We recommend using a stale read value of 15 seconds. This recommendation is based on the fact that the leader typically updates the replicas with the latest safe timestamp every 10 seconds. So, with 15 seconds staleness, the replica will likely know from its internal state that it is up-to-date to serve the reads and can immediately serve the read without communicating with the leader. Note that you can set a staleness value lesser than 15 seconds. However, in this situation, it’s likely that for some reads, the replica may not be sure whether it has the up-to-date data and may contact the leader, resulting in a higher read latency.

To summarize
Strong reads | Stale reads |
Higher latency for cross region reads | Low latency |
Guaranteed to provide latest data | Data read can be stale |
Required for applications that need to read their writes | Useful for latency sensitive applications that can tolerate stale data |
To Conclude
While being strongly consistent and highly available, Cloud Spanner provides different instance configurations, replica types, and read types (strong or stale) that you can use to meet your application’s latency and failure resiliency requirements. We hope that this blog will help you better understand the differences and choose the configuration that is just right for you.
To get started, create a Cloud Spanner instance in your GCP account or in a Spanner Qwiklab and try the new query exerience.



