Provisioning Cloud Spanner using Terraform
Stefan Serban
Software Engineering Manager
Overview
Cloud Spanner is a fully managed relational database built for scale with strong consistency and up to 99.999% availability. Key features include the following:
- ACID transactions, SQL queries (ANSI 2011 with extensions) and global scale.
- Automatic sharding - optimizes performance by automatically sharding the data based on request load and size of the data.
- Fully managed - Synchronous replication and maintenance are handled automatically.
- Flexible configurations - Depending on the workload, Cloud Spanner instances can be provisioned as either regional or multi-regional (spanning one continent or three continents).
- Online schema Changes - Cloud Spanner users can make a schema change, whether it’s adding a column or adding an index, while serving traffic with zero downtime.
In this blog post, we will talk about how to deploy a sample application on Cloud Run with a Cloud Spanner backend using Terraform templates. We will also learn how to manage a production-grade Cloud Spanner instance using Terraform, by starting with a small instance and scaling up by adding more nodes or processing units.
Terraform for Cloud Spanner
What is Terraform?
Terraform is a popular open-source infrastructure-as-code tool developed by HashiCorp, that provides a consistent CLI to manage hundreds of cloud services. It codifies cloud APIs into declarative configuration files. Terraform allows you to declare an entire GCP environment as code, which can then be version-controlled.
Benefits of using Terraform with Cloud Spanner
Terraform is very useful for provisioning scalable Cloud Spanner instances and databases in real-world, production environments. It allows for easier configuration management and version control and enables repeatability across regions and projects.
Organizations using Terraform to manage their cloud infrastructure today can easily include Cloud Spanner into their existing infrastructure-as-code framework.
The Cloud Spanner with Terraform codelab offers an excellent introduction to the provisioning of instances, creating and modifying databases, and scaling a Cloud Spanner instance with more nodes. The codelab is a great way to get started. In the next few paragraphs, we discuss a few details that go beyond what we cover in the codelab.
Specifying a regional configuration
Cloud Spanner instances can be launched either regionally or in a multi-region. Take a look at Instances in the official documentation (under “regional configurations” and “multi-region configurations”) for a list of the configuration options available.
For regional instances, add the “regional-” prefix to the instance names in the list below. Example: to provision an instance in Montreal, your Terraform template will have config = "regional-northamerica-northeast1"
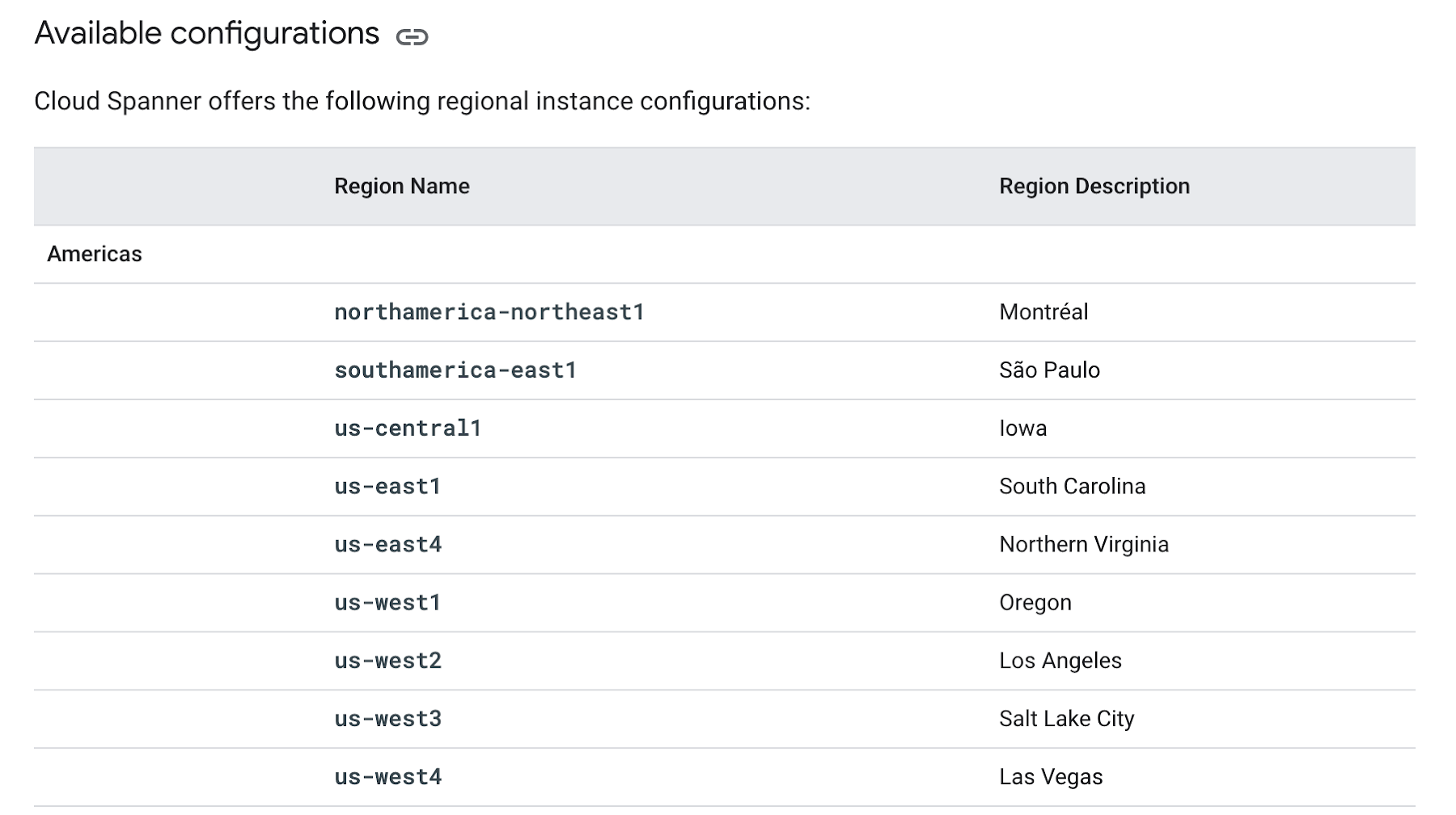
screenshot from: Google Cloud Documentation
For multi-region instances, you can use the region name as-is from the documentation. Example - asia1 for a one-continent instance in Asia or nam-eur-asia1 for a three-continent instance.
Modifying Cloud Spanner instance properties
Note that properties such as the amount of compute capacity (via num_nodes or processing_units), display name, and labels can be modified when making changes to an existing Cloud Spanner instance via Terraform. However, changing the instance name (the instance identifier on the GCP console) will result in the cluster being destroyed and recreated.
As mentioned above, compute capacity (a.k.a. the instance size) can also be defined in terms of processing_units. For example, the compute capacity defined below would be 1/10th of a node, while a value of 1000 would be one full node.
Creating databases and executing DDL commands
Finally, Cloud Spanner Terraform resources also support creating databases and executing DDL as part of the template.
The DDL support in the Terraform resource is a useful feature for initializing a database schema for smaller applications.
Limitations of Terraform with Cloud Spanner
Managing database schemas
Database schemas tend to change periodically. Terraform has very limited support database schema updates - changes to the DDL, particularly those that are not append-only, will require dropping and re-creating the database. Therefore, we don’t recommend using Terraform to manage the schemas of Cloud Spanner databases. Instead, we recommend using a schema versioning tool like Liquibase. A Liquibase extension with Cloud Spanner support was released recently under the Cloud Spanner Ecosystem. Here is the official documentation.
Deploying a sample app
For demonstration purposes, we’re going to use a sample stock price visualization app called OmegaTrade. This application stores the stock prices in Cloud Spanner and renders visualizations using Google Charts.
To learn more about the app and its integration with Cloud Spanner, see this blog post.
Now, to the fun part! We will deploy this application to Cloud Run using Terraform templates. We chose Cloud Run because it abstracts away infrastructure management and scales up or down automatically almost instantaneously depending on traffic. Let’s get started!
As prerequisites, please ensure that you have:
Access to a new or existing GCP project with one of the sets of roles listed below:
Owner
Editor + Cloud Run Admin + Storage Admin
Cloud Run Admin + Service Usage Admin + Cloud Spanner Admin + Storage Admin
Enabled billing on the above GCP project.
Installed and initialized the Google Cloud SDK.
Installed and configured Docker on your machine.
Installed and configured Git on your machine.
NOTE - Please ensure that your permissions are not restricted by any organizational policies.
We are deploying this application using Cloud Shell. If you are going through these steps on your local machine, and assuming you have already installed the Cloud SDK, you can execute the following command to authenticate.gcloud auth application-default login
Choose your Google account with access to the required GCP project and enter the Project ID when prompted.
Next, we need to ensure the gcloud configuration is set up correctly. You may want to start with a new configuration by using the create command. Below, we are enabling authentication, unsetting any API endpoint URL set previously, and setting the GCP project we intend to use in the default gcloud configuration. Replace [Your-Project-ID] below with the ID of your GCP project.
Before continuing further, let’s make sure our Terraform version is up to date (we need Terraform version 0.13.1 and above).
If needed, you can go to the official Terraform download page to download and install the latest version.
Next, let’s enable Google Cloud APIs for Cloud Spanner, Container Registry, and Cloud Run. Note: you could also use Terraform to accomplish this, instead of running the commands manually.
Now, let’s clone the repository that contains Terraform modules for Cloud Run, Cloud Spanner and GCE (for a Cloud Spanner emulator instance, which will be discussed in a future blog post).
Take a look at the directory structure below.
The examples folder has Cloud Spanner and Cloud Run Terraform examples, with their corresponding Terraform modules located in the modules folder.
Note: By default we have defined the compute capacity in terms of number of nodes in these templates. In case you want to define your compute capacity using processing units instead of nodes, you will need to uncomment the lines of code for processing_units in each of the examples and modules, and comment out the corresponding lines for num_nodes. The two options are mutually exclusive. To find all the relevant files to modify, you can execute
Note that as of the time of this writing, the smallest compute capacity available is 100 processing units (or 1/10th of a node).
Launching Cloud Spanner
We will now launch a single-node Cloud Spanner instance in the us-west1 region. The template also creates a database and the necessary tables for the OmegaTrade application using the DDL specified in the template.
Take a look at the terraform.tfvars file to customize the compute capacity, region, and number of nodes or processing units.
Enter your GCP project ID (without the square brackets), make any other changes you’d like, and save.
In case you want to define your compute capacity using processing units instead of nodes, you can specify a value for spanner_processing_units instead of spanner_nodes and follow the instructions at the end of the previous section.
Next, let’s initialize Terraform, and make sure that we have the correct versions of the providers installed
Analyze the execution plan,
And apply the changes.
Terraform will ask for your confirmation before applying.
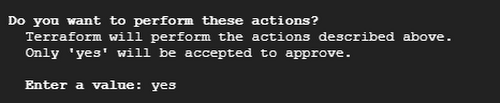
You should see the Cloud Spanner instance successfully provisioned .
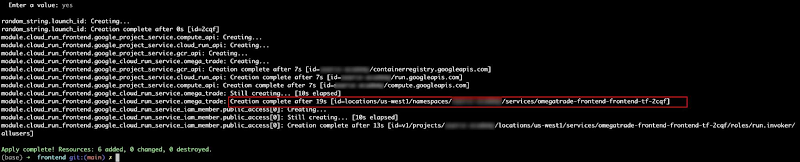
Click into the hamburger menu at the top left and select Spanner to verify the outcome on the GCP console.
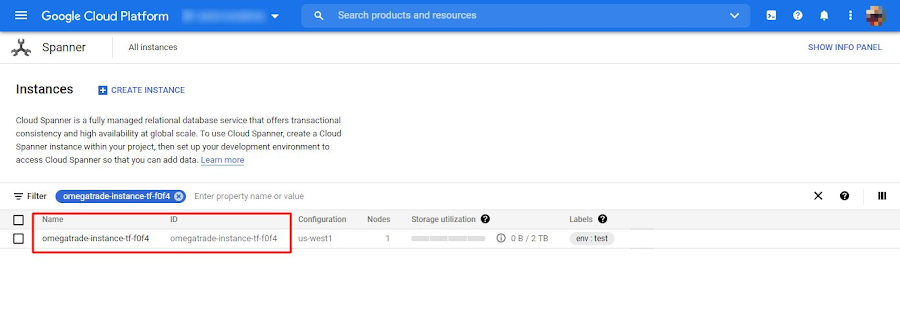
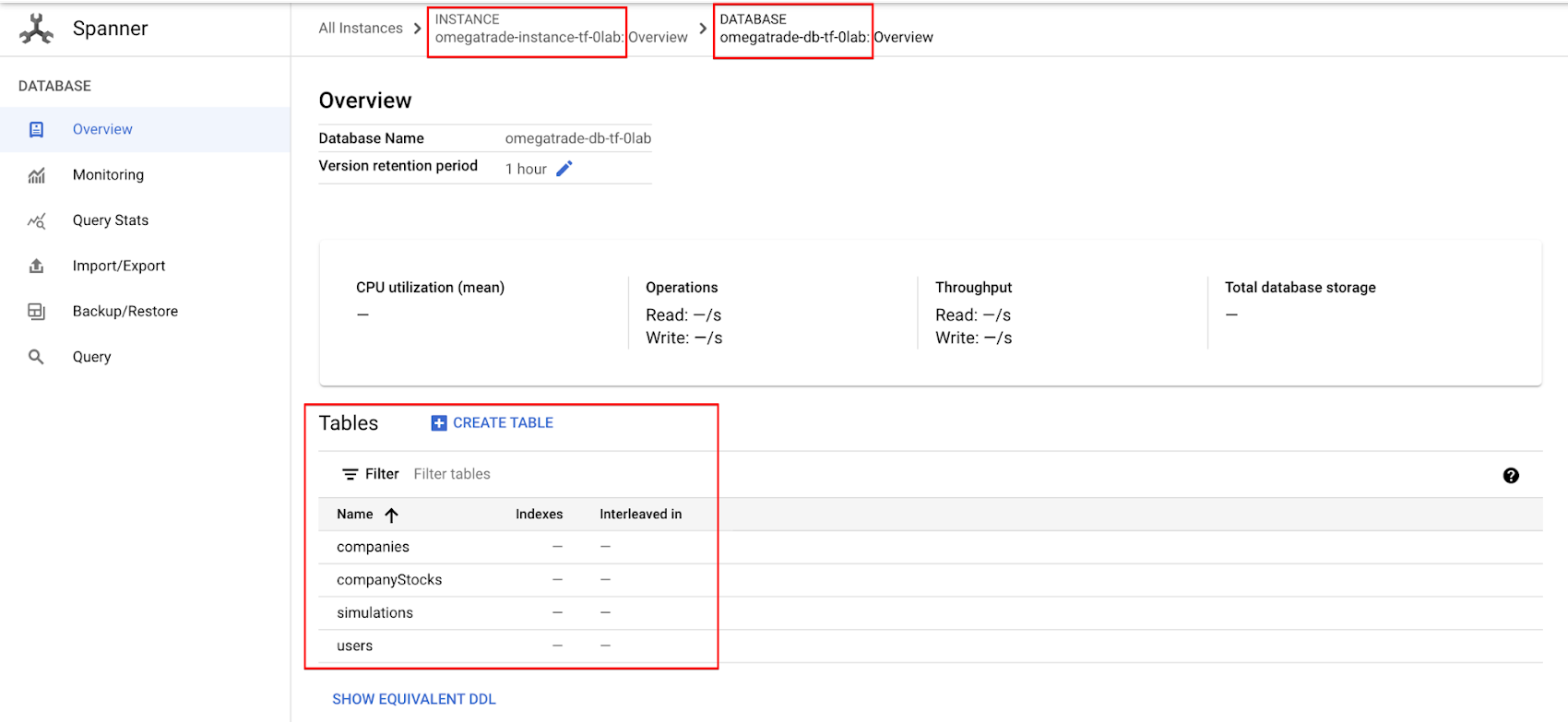
You can find the instance and database created, along with the necessary tables for the OmegaTrade application.
The above example provisioned a single node instance in the us-west1 region. If you would like to launch in a different region (different instance configuration) with multiple nodes, simply edit the terraform.tfvars file and set a different instance configuration instead of spanner_config = "regional-us-west1".
Deploying the backend to Cloud Run
We are going to be deploying two different services to Cloud Run: omegatrade/frontend and omegatrade/backend.NOTE - Please ensure that your permissions are not restricted by any organizational policies, or you may run into an IAM-related issue at the apply stage later on.
Now that the Cloud Spanner instance, database, and tables are in place, let’s build and deploy the backend service to Cloud Run. The frontend has a dependency on the backend URL, so we will start with the backend.
In the backend folder, we will create a .env file and insert some seed data into the database we created in the previous section. We begin by setting the gcp-project-id, spanner-instance-id, and spanner-database-id to the appropriate values that we got from the GCP console (omitting the square brackets).
Then, we run the following command to populate the seed data.
Next, we build the image from the dockerfile and push it to GCR. We will change the commands below to reflect our GCP project ID and run them.
We will now go back to the Terraform examples directory and provision the backend service of the OmegaTrade application.
Like the Cloud Spanner example you have seen in the previous section, you can quickly edit the terraform.tfvars file to make changes according to your environment and deploy. Since the Terraform template adds a suffix to the instance name and DB name, you might want to get the exact instance name and database name from the GCP console. The backend_container_image_path is the same path that you used in the docker push command above.
NOTE: In these templates, we follow the standard practice of using variables.tf or tfvars files to define variables and values. This is particularly useful when we have multiple resources with similar configuration, as while upgrading them the values need to be changed in only one place.
Here is how my file looks with all the details except the project ID filled in.
Next, let’s initialize Terraform and validate the plan.
Now, we’re ready to deploy backend service. If you get an IAM-related error at this stage, it is likely because of an organizational policy of the organization that the project is hosted in. You may need to contact your organization admin or start over with a project in a different organization that does not have this restriction.
Terraform will ask for your confirmation before applying.
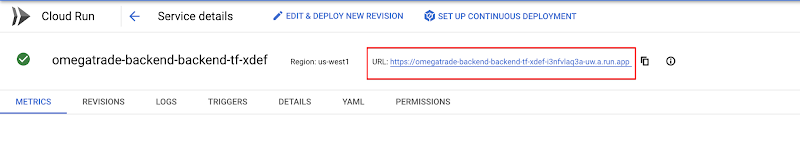
You should now see the backend service up and running.
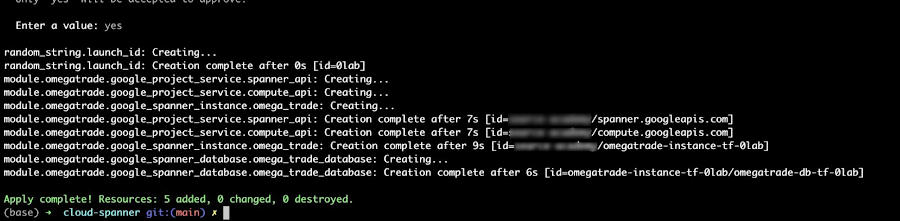
Check Cloud Run in the GCP console and locate the new service.
Write down its URL. We will use it in the frontend configuration in the next section.
Deploying the frontend to Cloud Run
Before we build the frontend service, we need to update the following file from the repo with the backend URL we got from the above step.
Change the base URL to the backend URL noted down in the previous section.
In the frontend folder, build the frontend service and push the image to GCR.
Go to the Terraform example for CloudRun (frontend service).
We will now provision the frontend service using the image we pushed to GCR above. Open the terraform.tfvars file and add the GCP project ID and frontend image path.
Here is what the file should look like after filling in most of the details.
Now, let’s deploy the frontend service.
Once again, Terraform will ask for your confirmation before applying.
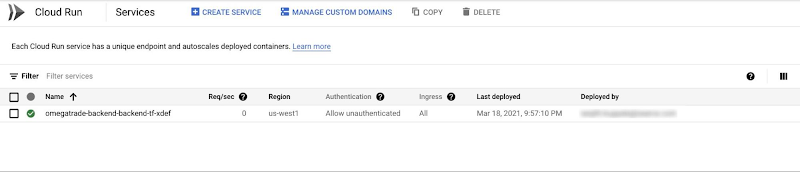
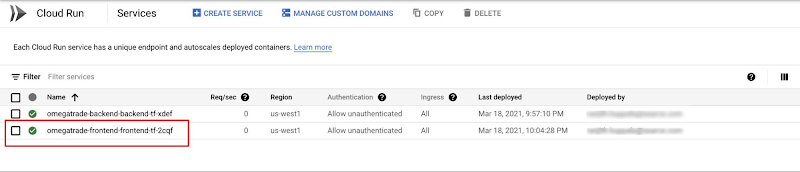
You should now see the frontend service up and running.
Check the services on the GCP console.
You will now be able to go to the frontend URL and interact with the application! You can interact with existing visualizations or simulate write activity on Cloud Spanner by visiting the Manage Simulations view in the application. Choose an existing company or add a new company, and choose an interval and number of records.
Scaling Cloud Spanner using Terraform
To scale the Cloud Spanner instance up or down, go back to the Cloud Spanner Terraform examples folder.
We currently have a single node Cloud Spanner instance in the us-west1 region. For production environments, this configuration may not be sufficient. Scaling Cloud Spanner can be achieved using our Terraform template.
Take a look at the terraform.tfvars file. We chose a regional instance with 1 node during the initial provisioning, running in the us-west1 region. We can now scale Cloud Spanner to the compute capacity necessary by running a terraform apply once again with an updated node count.
An example .tfvars file to scale the instance is available as terraform.scale.tfvars as shown below. Specify the same instance ID and database name as initially used. Note that the Terraform template randomizes the names of the instance and database by adding a random suffix, but while scaling you just need to use the original names.
Edit the terraform.scale.tfvars file with your project ID
In case you defined your compute capacity using processing units instead of nodes, you can follow the same steps to resize it, by specifying an updated value for spanner_processing_units instead of spanner_nodes and commenting/uncommenting the appropriate lines in the script as noted just above the Launching Cloud Spanner section earlier in this post.
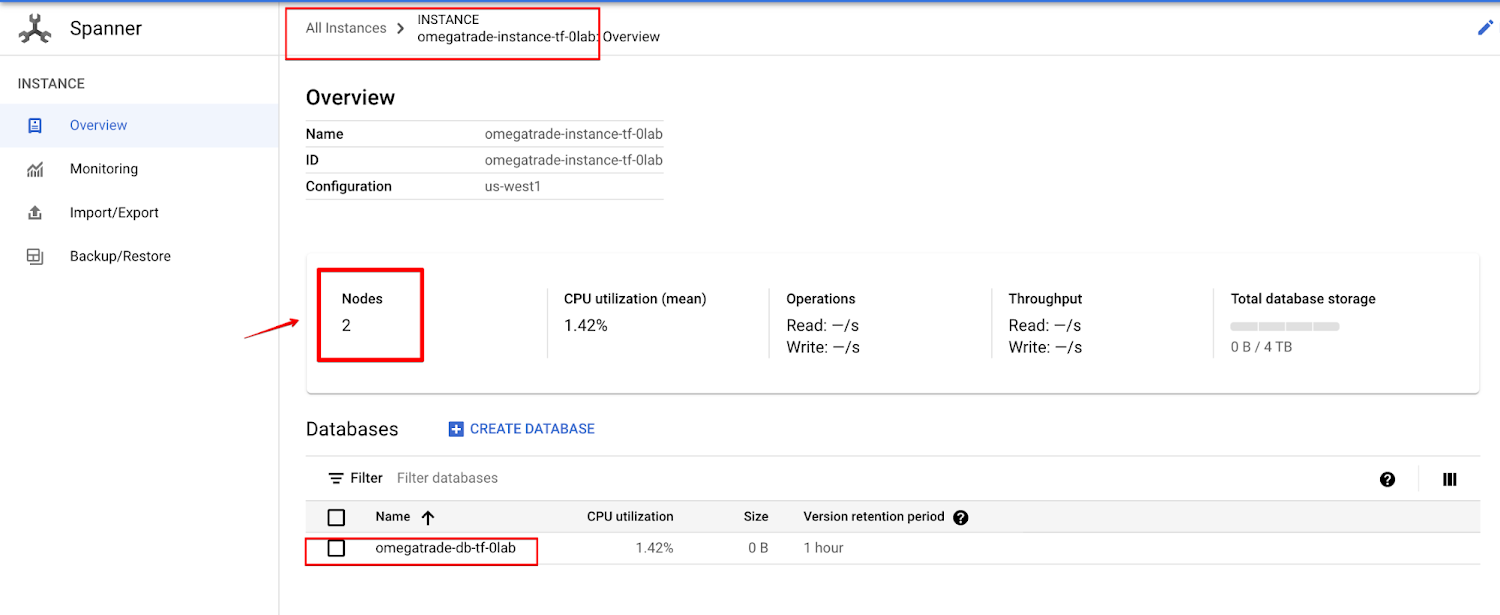
Apply changes to scale the instance from 1 node to 2 nodes.
It may take a few seconds for the changes to take effect.

Verify the changes on the GCP console
Conclusion
We have seen how easy it is to provision Cloud Spanner instances and create databases and tables using Terraform using a sample application deployment. We have also seen how to scale Cloud Spanner using Terraform after the initial deployment. Armed with this knowledge, you are ready to try out the code modules in this repository and set up your own Cloud Spanner instances with Terraform.
To learn more about using Terraform with Cloud Spanner, visit




